


Penerangan Mendalam Tentang Kepintaran Buatan yang Mudah Difahami (Bhgn 1)

Artikel ini ialah terjemahan “Machine Learning is Fun part 1” oleh Adam Geitgey.
Kalau terjemah secara langsung, tajuk artikel sepatutnya berbunyi “Seronoknya Pembelajaran Mesin”. Tapi sebab SEO dan perkataan pembelajaran mesin tak digunakan secara meluas dalam bahasa Malaysia, saya ubah tajuk dan guna perkataan Kepintaran Buatan.
Saya terjemah artikel ini sebab saya rasa ini adalah antara artikel mendalam dan mudah faham pasal kepintaran buatan dan teknologi di sebalik tabir.
Saya sedaya upaya menterjemah sedekat mungkin dengan maksud penulis asal. Walaubagaimanapun, untuk orang ramai lebih mudah faham, saya akan mencelah dan mengubah struktur ayat sedikit sebanyak.
Ada masalah? Tak setuju dengan terjemahan saya? Ada pendapat? Komen di bawah atau tweet saya.
Pernah anda dengar orang bercakap pasal kepintaran buatan, AI, machine learning tapi masih kabur dengan maksud perkataan tu? Anda pun dah letih dah terangguk-angguk apabila kawan-kawan berborak pasal topik ni? Jom ubah. Fakhrul: BUKAN ubah kerajaan! Ubah dari kabur-kabur kepada tahu sungguh-sungguh.
Artikel ini adalah panduan untuk semua orang yang nak tahu pasal pembelajaran mesin, ML (machine learning) tapi tak tahu mana nak mula. Saya bayangkan ramai orang yang baca artikel di Wikipedia, pastu kecewa dan berharap sangat ada orang yang boleh beri penerangan yang mendalam tapi mudah faham. Inilah tujuan utama artikel ini.
Matlamatnya ialah memberi kefahaman kepada semua orang. Sebab itu, perkataaan dan ayat dalam artikel ini ditulis lebih umum dan meluas. Asalkan artikel ini dapat menarik orang supaya semakin berminat tentang ML, maka matlamatnya tercapai.
Fakhrullah mencelah:
Kepintaran buatan, (Artificial Intelligence) AI ialah objek atau alat yang boleh cuba untuk mendekati cara manusia memahami sesuatu perkara.
Manakala pembelajaran mesin, ML pula ialah salah satu cara untuk mencapai kepintaran buatan, yang sangat menyerlah pada akhir-akhir ini.
Apa itu pembelajaran mesin, ML (machine learning)
Pembelajaran mesin, ML ialah idea untuk algoritma yang boleh memberitahu sesuatu yang menarik, berdasarkan kumpulan data tanpa perlu tulis kod khusus untuk masalah tertentu. Daripada tulis kod, anda cuma perlu masukkan data dan akan terbinalah satu kesimpulan berdasarkan data yang diberi.
Contohnya, salah satu daripada algoritma ialah pengkelasan algoritma (classification algorithm). algoritma ini akan memisahkan data kepada kelompok yang berbeza. Pengkelasan algoritma yang digunakan untuk mengenal nombor yang ditulis tangan, boleh juga digunakan untuk mengenal emel sampah atau bukan sampah tanpa mengubah sebaris kod pun. algoritma yang sama tetapi bila diberi data latihan berbeza menghasilkan pengkelasan dengan logik yang berbeza.
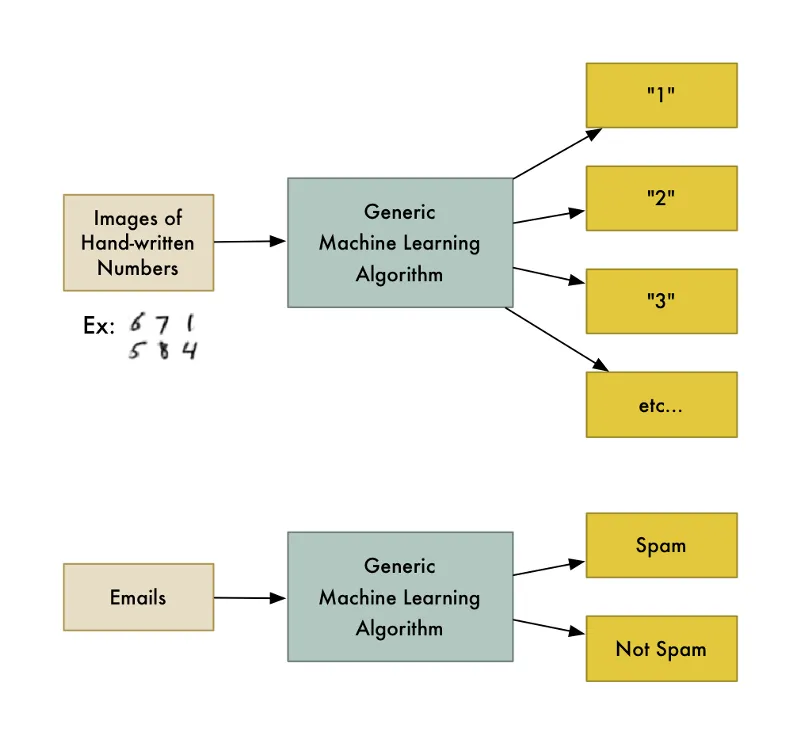
Pembelajaran mesin, ML ialah satu frasa yang merangkumi kebanyakan jenis algoritma sebegini.
Dua jenis algoritma Pembelajaran Mesin
Anda boleh anggap algoritma untuk pembelajaran mesin boleh jadi salah satu daripada 2 kategori berikut. Sama ada pembelajaran terkawal (supervised learning) atau pembelajaran tak dikawal (unsupervised learning). Perbezaannya nampak mudah, tapi sangat penting.
Pembelajaran terkawal
Katakan anda seorang agen hartanah. Peniagaan anda semakin maju, jadi anda upah agen-agen pelatih yang baru untuk menolong anda. Tapi ada satu masalah, bagi anda yang berpengalaman, sekali pandang je, anda dah boleh agak berapa nilai sesebuah rumah. Tapi, pelatih anda tak de pengalaman, jadi mereka tak tahu macam mana nak nilai harga rumah dengan baik.
Untuk menolong pelatih anda (dan mungkin tambah cuti untuk anda sendiri), anda ambil keputusan untuk buat sebuah aplikasi kecil yang boleh anggarkan harga sesebuah rumah tu beradasarkan saiz, kejiranan, lain-lain dan bandingkan dengan rumah-rumah yang anda pernah jual sebelum ini.
Jadi setiap kali ada orang jual rumah di bandar anda dalam tempoh 3 bulan, anda tulis matlumatnya. Untuk setiap rumah, anda tulis: jumlah bilik, saiz rumah dalam kaki persegi, kejiranan dll. Tapi yang paling penting, anda tulis harga jualan akhir rumah tersebut.
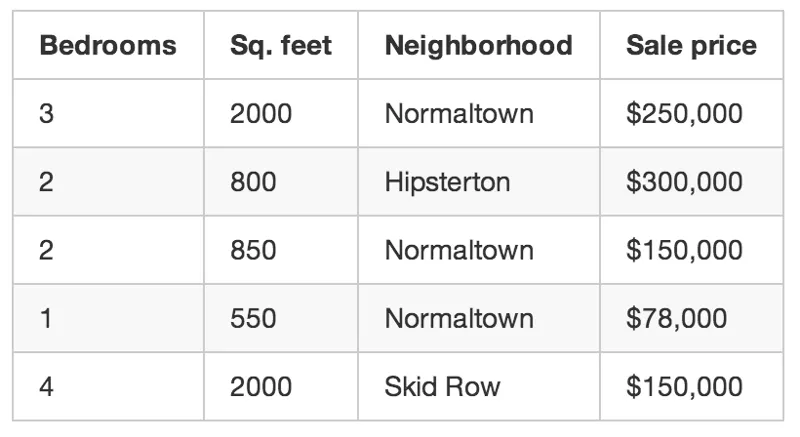
Menggunakan data latihan tersebut, kita nak buat satu program yang boleh anggar berapa harga rumah lain yang berada dalam kawasan anda.

Ini dipanggil pembelajaran terkawal. Anda dah pun tahu harga setiap rumah dijual, dengan kata lain, anda tahu jawapan kepada masalah dan boleh belajar dari jawapan tersebut untuk memahami logik kepada penyelesaian.
Untuk membina aplikasi, anda beri data latihan tentang setiap rumah ke algoritma pembelajaran mesin anda. algoritma tersebut akan cuba mendapatkan persamaan matematik yang sesuai dengan data yang diberikan.
Ini seolah-olah seperti menyelesaikan ujian matematik yang operasi-operasi matematik dipadam:

Daripada sini, bolehkah anda cari masalah matematik yang ada dalam ujian? Anda tahu anda perlu ‘buat sesuatu’ dengan nombor di sebelah kiri untuk mendapat jawapan di sebelah kanan.
Dalam pembelajaran terkawal, anda menyerahkan tugas mencari hubungan tersebut kepada komputer. Setelah anda tahu matematik yang diperlukan untuk menyelesaikan masalah ini, anda boleh selesaikan masalah-masalah lain yang sama jenis.
Pembelajaran tak dikawal
Jom balik kepada contoh asal tentang agen hartanah. Macam mana kalau anda tak tahu harga setiap rumah dijual? Sekalipun anda hanya tahu maklumat-maklumat tentang saiz rumah, kejiranan, dan lain-lain berkenaan rumah tersebut, sebenarnya anda masih boleh hasilkan sesuatu yang menarik. Ini dipanggil pembelajaran tak dikawal.
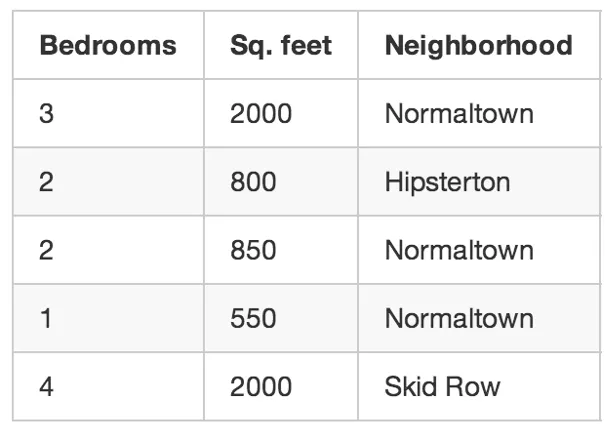
Hal ini seolah-olah, ada orang beri anda sehelai kertas menandungi senarai nombor, kemudian cakap ‘Saya tak tahu apa maksud nombor-nombor ini semua, tapi anda mungkin boleh cari corak, pola, kelompok, atau apa-apa lah. Semoga berjaya! 😎’
Jadi, apa yang anda boleh buat dengan data ini? Untuk permulaan, anda mungkin dah ada algoritma yang dapat mengenal pasti bahagian pemasaran yang berbeza dalam data anda. Mungkin anda akan dapati pembeli rumah di kejiranan berdekatan dengan kolej tempatan lebih berminat kepada rumah kecil dengan bilik yang banyak, tetapi pembeli di kawasan pinggir bandar lebih kepada rumah dengan 3 bilik dan ada ruang laman yang luas. Pengetahuan tentang perbezaan pelanggan boleh membantu pemasaran lebih efektif.
Satu lagi perkara menarik yang anda boleh lakukan secara automatik ialah mengenal pasti mana-mana rumah yang jauh berbeza dengan rumah lain. Mungkin rumah yang berbeza itu ialah sebuah rumah agam yang besar. Jadi bolehlah anda fokuskan jualan rumah tu kepada orang-orang kaya dan peroleh keuntungan yang lebih besar.
Kita akan fokuskan kepada pembelajaran terkawal dalam artikel ini selanjutnya. Tapi bukan bermaksud pembelajaran tak dikawal tak berguna atau tak menarik. Malahan, pembelajaran tak dikawal semakin hari semakin penting selari dengan algoritma yang semakin baik. Sebab ia boleh digunakan tanpa perlu menandakan data dengan jawapan yang betul.
Nota sampingan: Ada banyak jenis lagi algoritma pembelajaran mesin. Tapi, ini adalah permulaan yang terbaik.
Hebat! Tapi bukankah kebolehan meneka anggaran harga barulah dipanggil sebagai “pembelajaran” ?
Sebagai seorang manusia, minda kita akan melihat pelbagai situasi dan belajar untuk mengawal situasi tanpa perlu arahan tertentu. Sekiranya anda jual rumah sekian lama, anda akan ada satu ‘perasaan’ harga yang tepat untuk sesebuah rumah, cara terbaik untuk mempromosi rumah tersebut, jenis pelanggan yang mungkin berminat dan lain-lain. Matlamat kajian kecerdasan buatan ialah untuk komputer meniru kebolehan manusia ini.
Tapi algoritma pembelajaran mesin masa kini belum cukup baik lagi. algoritma-algoritma ini hanya berfungsi apabila masalah lebih khusus (spesifik) dan terhad. Mungkin maksud lebih jelas untuk “pembelajaran” dalam hal ini ialah “memikirkan satu persamaan untuk menyelesaikan sesuatu masalah berdasarkan sebahagian dari data”.
Malangnya “Mesin memikirkan satu persamaan untuk menyelesaikan sesuatu masalah berdasarkan sebahagian dari data” bukanlah suatu nama yang hebat. Jadi, kita berakhir dengan perkataan Pembelajaran Mesin.
Semestinya, jika anda membaca ini 50 tahun di masa hadapan (2064 Masihi) dan kita manusia telah pun berjaya memikirkan algoritma untuk kecerdasan buatan, maka seluruh artikel ini mungkin kelihatan agak pelik. Boleh jadi, anda patut berhenti membaca dan suruh je robot anda buat sandwich, cis! manusia masa depan. 😛
Jom tulis kod, buat program meramal harga rumah
Jadi, macam anda nak menulis sebuah program meramal harga sesebuah rumah seperti contoh kita di atas? Fikir tentang sejenak sebelum anda terus membaca.
Fakhrullah:
OK. Jangan terus membaca lagi, jika anda belum berangan, program yang macam mana anda akan buat. Membaca adalah aktiviti pasif. Untuk menghubungkan saraf-saraf otak, anda kena berfikir.
Berfikir sejenak, kod yang macam mana anda akan tulis untuk meneka harga rumah?. Befikir, baik untuk minda.
Jika anda tidak tahu apa-apa tentang pembelajaran mesin, anda mungkin akan menulis program dengan pelbagai peraturan untuk anggar harga seperti dibawah:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# In my area, the average house costs $200 per sqft
# Dalam kawasan saya, harga biasa sebuah rumah bernilai $200 untuk sekaki persegi
price_per_sqft = 200
if neighborhood == "hipsterton":
# but some areas cost a bit more
# tapi di sesetengah kawasan harganya lebih mahal
price_per_sqft = 400
elif neighborhood == "skid row":
# and some areas cost less
# dan sesetengah kawasan pula lebih rendah
price_per_sqft = 100
# start with a base price estimate based on how big the place is
# mula dengan harga asas anggaran berdasarkan berapa besar suatu kawasan tersebut
price = price_per_sqft * sqft
# now adjust our estimate based on the number of bedrooms
# sekarang ubah anggaran berdasarkan jumlah bilik
if num_of_bedrooms == 0:
# Studio apartments are cheap
# pangsapuri studi lebih murah
price = price — 20000
else:
# places with more bedrooms are usually more valuable
# kawasan dengan lebih banyak bilik biasanya lebih bernilai
price = price + (num_of_bedrooms * 1000)
return priceJika anda kekal dengan idea ini dan ubah sedikit demi sedikit, anda mungkin akan berjaya menghasilkan sebuah program yang berfungsi dengan baik. Tapi program takkan pernah sempurna dan semakin lama semakin susah untuk diselia apabila harga pasaran berubah.
Bukankah lagi baik sekiranya komputer boleh bina fungsi seperti ini untuk anda? Siapa peduli dengan macam fungsi sebenarnya ditulis, selagi ia meramalkan nombor yang tepat:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = <computer, plz do some math for me>
return priceSalah satu cara memikirkan masalah ini ialah, dengan menganggap harga seumpama sup yang sedap dan bahan-bahan dalamnya ialah jumlah bilik, keluasan kaki persegi dan kejiranan. Sekiranya anda dapat menjangkakan berapa banyak setiap bahan-bahan boleh mempengaruhi harga akhir, mungkin ada satu nisbah yang tepat untuk bahan-bahan yang dicampurkan bagi menghasilkan harga akhir.
Ini boleh mengurangkan fungsi asal anda (yang penuh dengan if-else tu) kepada sesuatu yang lebih mudah seperti:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * .841231951398213
# and a big pinch of that
price += sqft * 1231.1231231
# maybe a handful of this
price += neighborhood * 2.3242341421
# and finally, just a little extra salt for good measure
price += 201.23432095
return pricePerhatikan nombor khas: .841231951398213, 1231.1231231, 2.3242341421, dan 201.23432095 dalam kod di atas. Ini semua adalah pekali-pekali kita. Andaikan kita dapat mencari pekali-pekali yang sempurna yang berguna untuk setiap jenis rumah, maka fungsi kita boleh meramal harga-harga rumah.
Cara kurang bijak untuk mencari pekali-pekali terbaik, boleh jadi seperti ini:
Langkah 1:
Mulakan dengan pekali-pekali yang ditetapkan 1.0:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * 1.0
# and a big pinch of that
price += sqft * 1.0
# maybe a handful of this
price += neighborhood * 1.0
# and finally, just a little extra salt for good measure
price += 1.0
return priceLangkah 2:
Jalankan fungsi anda tadi untuk setiap rumah. Kemudian bandingkan harga sebenar dan harga yang dijana oleh fungsi anda:
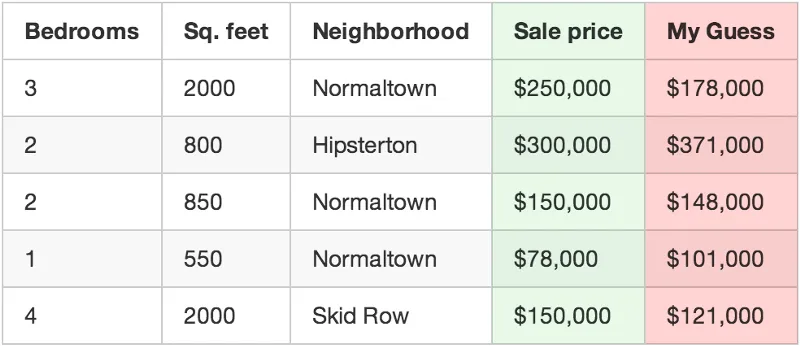
Fakhrullah:
Saya rasa penerangan di sini agak mengelirukan untuk orang tak tahu apa itu the least square. Tapi teruskan membaca biarlah tak berapa faham lagi pun. Kalau ada orang berminat, saya boleh terangkan pasal the least square ni dalam artikel yang lain dengan penerangan bergrafik. Berminat? Jangan lupa komen.
Contoh, jika harga sebenar rumah pertama yang anda jual ialah $250,000, tapi fungsi anda meramalkan ia dijual pada harga $180,000, bermakna bezanya ialah $72,000 untuk sebuah rumah itu.
Sekarang tambah semua beza yang dikuasa dua dalam koleksi data anda. Katakan anda ada 500 buah rumah terjual dalam koleksi data, dan kuasa dua beza harga sebenar dengan harga dari fungsi anda keseluruhannya ialah $86,123,373. Maksudnya, itulah nilai kesilapan fungsi anda.
Sekarang ambil jumlahnya dan bahagikan dengan 500 untuk mendapatkan purata beza harga untuk setiap rumah. Kita sebut purata kesilapan ini sebagai kos fungsi anda.
Seandainya anda dapat mengurangkan kos ini menjadi sifar (0) dengan cara mengubah nilai pekali-pekali, fungsi anda akan jadi sempurna. Ini bererti dalam setiap hal, fungsi anda meneka harga akhir untuk setiap buah rumah berdasarkan data yang diberikan dengan sempurna. Jadi itulah tujuan kita. Iaitu menghasil kos sekecil-kecilnya dengan mencuba pelbagai nilai untuk pekali-pekali.
Langkah 3:
Ulang langkah 2 berulang kali sehinggalah semua kemungkinan kombinasi pekali-pekali dicuba. Kombinasi pekali yang menghasilkan kos yang paling dekat dengan sifar, itulah yang kita guna. Apabila anda menemui pekali-pekali yang berfungsi, maka anda telah selesaikan masalah.
Masa cabar minda
Mudahkan? Fikir balik apa yang anda dah buat. Anda ambil sebahagian data, berikan kepada 3 fungsi umum. Langkah yang sangat mudah dan anda hasilkan satu fungsi yang boleh meramal mana-mana harga rumah di kawasan anda.
Tapi di sini ada beberapa fakta yang boleh meletupkan minda anda:
-
Kajian dalam banyak bidang (seperti bahasa/terjemahan) dalam 40 tahun terakhir ini menunjukkan algoritma pembelajaran umum seperti ini mengatasi keupayaan manusia yang cuba datang dengan peraturan tersendiri. Cara kurang bijak melalui pembelajaran mesin mengalahkan pakar manusia.
-
Akhirnya fungsi yang anda peroleh sangat tidak bijak. Fungsi ini tidak tahu apa itu keluasan kaki persegi, kejiranan atau jumlah bilik. Fungsi ini cuma tahu, bahawa ia perlu kacau beberapa nilai untuk semua nombor tu bagi menghasilkan jawapan yang tepat.
-
Boleh dikatakan anda sendiri pun tak tahu, kenapa pekali-pekali tertentu berfungsi menghasilkan jawapan yang tepat. Jadi, anda baru sahaja menulis satu fungsi yang anda sendiri pun tak berapa faham, tapi dibuktikan berguna.
-
Bayangkan, daripada mengambil parameter seperti
sqftdannum_of_bedrooms, fungsi ramalan anda boleh mengambil sekelompok nombor. Katakan setiap nombor mewakili kecerahan satu piksel dan sebuah gambar yang diambil dari kamera yang dipasang diatas bumbung kereta. Sekarang, katakan daripada meramal nilai hargaprice, fungsi ini meramal darjah untuk memusingkan stereng (degrees_to_turn_steering_wheel). Sekarang anda baru sahaja membina sebuah fungsi yang membuatkan kereta kemudi sendiri!
Hebatkan?
Fakhrullah:
Kereta kemudi sendiri, bukan kereta pandu sendiri, sebab kita tak buat pembelajaran mesin untuk kelajuan kereta lagi 😆
Macam mana dengan bab ‘cuba pelbagai nombor’ di langkah 3?
Ok, sudah tentu anda takkan mampu nak cuba setiap kombinasi untuk semua pekali bagi mencari kombinasi terbaik. Ini pasti akan ambil masa selama-lamanya sebab anda takkan pernah kehabisan nombor untuk dicuba.
Untuk mengelakkan itu, ahli Matematik telah menjumpai berbagai-bagai cara bijak untuk mencari pekali-pekali terbaik tanpa perlu cuba berkali-kali. Salah satu caranya ialah:
Mula-mula, tulis satu persamaan ringkas untuk menggambarkan langkah di 2 di atas:
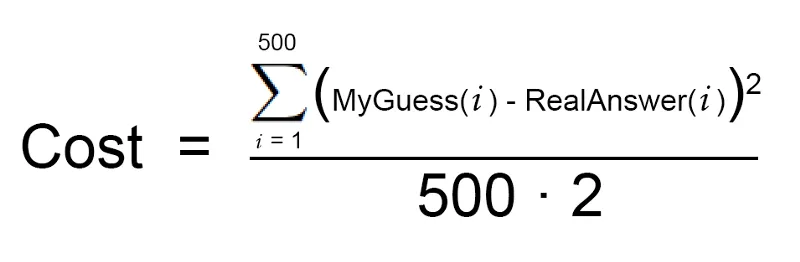
Sekarang jom tulis balik persamaan di atas, tapi kali ini kita guna pelbagai simbol-simbol khusus dalam matematik untuk pembelajaran mesin (abaikan dulu pemahaman simbol khusus ini):
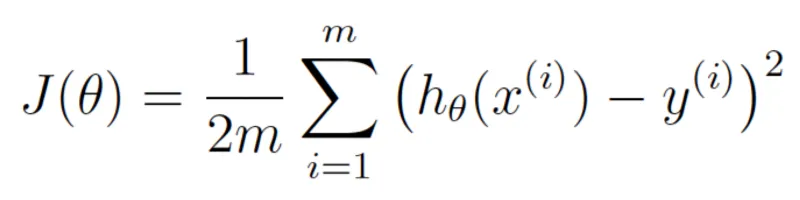
Persamaan ini melambangkan betapa salahnya fungsi anggaran harga untuk pekali-pekali yang kita dah pun tetapkan.
Jika kita grafkan persamaan kos ini dengan pelbagai kemungkinan nilai untuk pekali-pekali (num_of_bedrooms, sqft), kita akan dapat graf yang kelihatan seperti ini:
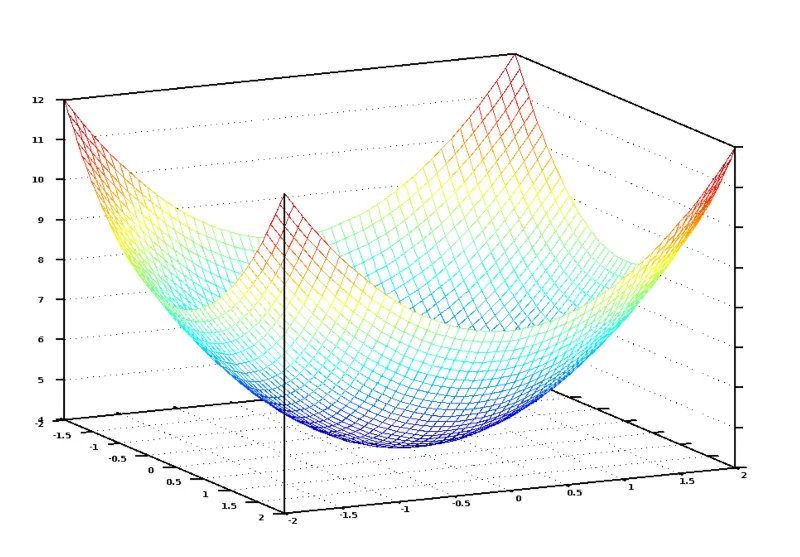
Dalam graf ini, titik berwarna biru paling bawah menunjukkan kos paling rendah. Inilah titik yang menjadikan fungsi kita paling tepat. Manakala, titik paling tinggi pula menjadikan fungsi kita paling salah. Jadi, jika kita boleh cari pekali-pekali yang membawa kita ke titik paling bawah dalam graf ini, kita akan dapat jawapannya.
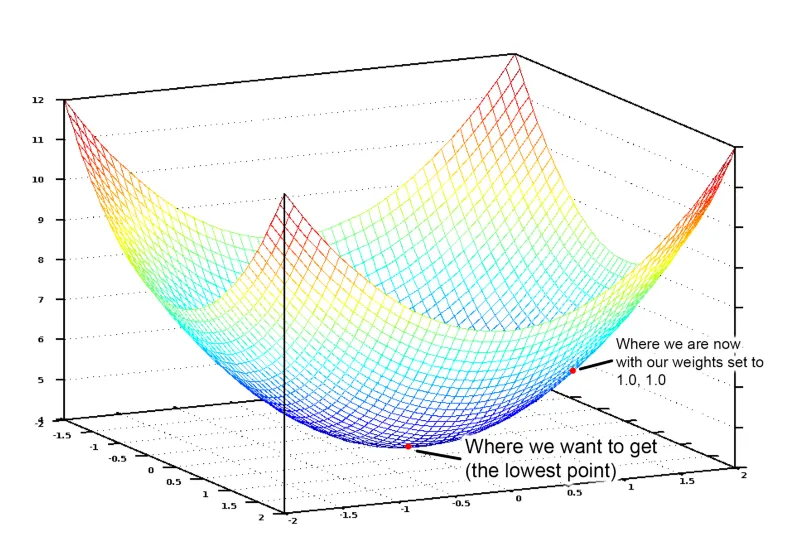
Jadi kita hanya perlu ubah pekali-pekali kita ‘menurun bukit’ dalam graf ini hingga ke titk paling bawah. Jika kita berterusan ubah pekali kita sedikit demi sedikit yang bergerak menuju ke titik paling bawah, akhirnya kita akan sampai tanpa perlu mencuba nilai pekali-pekali yang banyak.
Jika anda ingat balik apa yang anda belajar dalam Kalkulus, anda mungkin ingat bahawa sekiranya anda ambil derivative suatu fungsi, ia akan menunjukkan cerun sesuatu fungsi tangen pada mana-mana titik. Dengan kata lain, ia tunjukkan kita arah mana menurun cerun pada mana-mana titik dalam graf. Kita boleh gunakan pengetahun ini untuk menuruni bukit.
Jadi jika kita kira sebahagian penghubung (derivative) fungsi kos kita dengan mematuhi setiap pekali-pekali kita, kemudian kita boleh tolak nilai untuk setiap pekali. Dengan itu, ia akan membawa kita selangkah mendekati titik paling bawah. Lakukan secara berterusan dan akhirnya kita akan sampai ke titik paling bawah. Maka, kita akan peroleh nilai terbaik untuk pekali-pekali kita. (Jika anda tak berapa faham, jangan risau dan teruskan membaca)
Fakhrullah:
Saya rasa penerangan ni lebih sesuai dilakukan dengan graf dan persamaan matematik. Jadi sesiapa yang rajin, boleh cuba terangkan dengan video dan papan putih mungkin.
Begitulah ringkasan tahap tinggi tentang salah satu cara untuk mencari pekali-pekali yang terbaik untuk fungsi anda, dan ia disebut batch kecerunan lekukan F: 😂😂😂 (batch gradient descent).
Apabila anda gunakan pakej pembelajaran mesin (yang dah dibuat pakar) untuk selesaikan masalah sebenar, semua masalah matematik di atas akan diselesaikan untuk anda. Tetapi sesuatu yang berguna untuk anda tangkap perkara yang sebenarnya terjadi.
Fakhrullah:
Pernah tak dengar, orang berkulit hitam lagi susah nak dapat kerja, lagi mudah dikategori sebagai penjenayah oleh algoritma pembelajaran mesin? Pernah tak dengar cerita Stephen Hawking dan Elon Musk komen supaya berhati-hati dalam menggunakan pembelajaran mesin?
Inilah sebabnya. Kita tak tahu dari mana datang pekali-pekali itu. Ia macam suatu nombor yang ajaib. Pembelajaran mesin ambil data-data dan hasilkan pekali-pekali tadi. Kita tahu data-datanya, tapi kita tak tahu rasional disebaliknya.
Masalah lagi besar apabila sesetengah syarikat seperti Google, Facebook dan lain-lain membuat keputusan untuk kita tanpa beritahu data apa yang mereka gunakan. ![Privacy International][privacy-international-website] ada banyak artikel membahaskan bab ini.
Kesimpulannya, saya rasa kita boleh anggap pembelajaran mesin macam orang yang sangat pandai, tapi masih boleh melakukan kesilapan.
Apa lagi yang anda suka-suka je langkau?
Tiga langkah algoritma yang telah saya terangkan ini dipanggil regresi linear pelbagai variasi F: 😂😂😂 (multivariate linear regression). Anda sedang meneka persamaan untuk satu garisan yang menepati semua titik data rumah-rumah. Kemudian anda guna persamaan untuk meneka harga jualan untuk rumah yang anda tak pernah jumpa sebelum ini berdasarkan tempat rumah itu muncul di atas garisan. Ini satu idea yang hebat dan anda boleh selesaikan masalah sebenar dengan cara ini.
Tetapi, cara yang saya tunjukkan mungkin boleh digunakan untuk masalah yang mudah dan mungkin tidak menjadi dalam semua hal. Salah satu sebabnya kemungkinan harga rumah tidak semudah melalui garisan yang berterusan.
Nasib baik kita ada banyak cara untuk mengatasinya. Ada pelbagai algoritma pembelajaran mesin yang boleh atasi data tak linear (seperti rangkaian saraf neural network* atau mesin sokongan vektor _Support Vector Machine? dengan kernel). Ada juga cara-cara menggunakan regresi linear lebih bijak yang membenarkan garisan lebih rumit mengena. Dalam semua hal, idea asas tentang perlunya mencari pekali-pekali terbaik masih terpakai.
Saya juga mengabaikan tentang overfitting. Sangat senang untuk datang dengan pekali-pekali yang sempurna meramalkan harga rumah yang berada dalam koleksi data asal. Tetapi tak pernah berguna untuk sebarang rumah yang tiada dalam data asal. Namun, ada cara untuk menyelesaikan masalah sebegini (seperti pembiasaan (regularization) dan menggunakan pengesahan-silang (cross-validation) data). Belajar mengatasi isu sebegini adalah kunci kepada cara mengadaptasikan pembelajaran mesin dengan berjaya.
Dalam kata lain, walaupun konsep asas sangat mudah, ia memerlukan kemahiran dan pengalaman untuk menggunakan pembelajaran mesin dan memperoleh hasil yang berguna. Tetapi, ianya suatu kemahiran yang boleh dipelajari oleh semua pembangun (developer).
Adakah pembelajaran mesin ni sihir (magik)
Setelah anda mula melihat bagaimana pembelajaran mesin digunakan dalam masalah yang kelihatan agak sukar (seperti mengenal pasti tulisan tangan), anda akan mula merasakan yang anda boleh guna pembelajaran mesin untuk menyelesaikan semua jenis masalah dan mendapat jawapan selagi mempunyai data yang mencukupi. Hanya masukkan data dan tunggu keajaiban komputer untuk mencari persamaan yang menepati data!
Tapi, yang penting kita kena ingat, bahawa pembelajaran mesin hanya boleh menyelesaikan masalah berdasarkan data yang anda ada.
Contoh, jika anda bina sebuah model untuk meramal harga rumah berdasarkan jenis pokok bunga dalam setiap rumah, ia takkan pernah berfungsi. Sebabnya, kewujudan jenis pokok bunga tidak ada sebarang kaitan dengan harga rumah. Oleh sebab itu, tidak kira berapa bersungguh pun ia cuba, komputer takkan pernah menjangka hubungan antara keduanya.

Jadi ingat, jika seorang manusia yang pakar pun tak dapat selesaikan masalah tertentu berdasarkan data yang ada secara manual, kemungkinan besar komputer pun tak mampu lakukannya. Malahan, fokuskan kepada masalah yang manusia boleh selesaikan, tapi dengan bantuan komputer masalah boleh diselesaikan lebih cepat.
Macam mana nak belajar lebih banyak lagi pasal Pembelajaran Mesin
Pada pendapat saya, masalah paling besar dengan pembelajaran mesin sekarang ialah ianya hanya berlegar dalam dunia pendidikan dan kelompok kajian komersial. Kurangnya sumber-sumber yang senang difahami oleh orang awam untuk mendapat pemahaman yang lebih mendalam tanpa perlu menjadi pakar. Tapi, sehari demi sehari, keadaan menjadi semakin baik.
Fakhrullah:
Artikel ini ditulis oleh Adam Geitgey pada May 2014. Dalam masa 3 tahun ni, sumber pengetahuan alhamdulillah, semakin bertambah.
Tapi macam biasa, sumber ilmu dalam Bahasa Melayu (Malaysia) tak nampak perkembangan. Tak pe lah kot, sebab orang Malaysia sekarang semua dah pandai Bahasa English. kan? 😛
Budak2 kecil pun dah mula belajar one two three dulu sebelum satu dua tiga. 😛Apa pun, sebab sayangkan bahasa, saya terus menulis artikel teknikal dalam bahasa kita dan cuba terjemahkan artikel ini.
Sikit-sikit saya terjemah, lepas seminggu lebih, akhirnya berjaya juga. Walaubagaimanapun ini adalah artikel pertama daripada 8 artikel dalam siri ini. Saya teringin untuk terjemahkan artikel-artikel, tapi tengoklah kalau ada masa dan ada permintaan. Nak kah baca lagi artikel sebegini dalam Bahasa Melayu? Komen kat bawah.
Rujuk artikel asal dalam BI dan lanjutannya.
Akhir sekali saya (Fakhrullah Padzil penterjemah) ingin berkongsi komik dari ComitStrip

Sumber: Commit Strip - AI inside