

Artikel ini ialah terjemahan "Machine Learning is Fun part 2" oleh Adam Geitgey. Sambungan dari terjemahan artikel sebelum ini.
Kalau terjemah secara langsung, tajuk artikel sepatutnya berbunyi "Seronoknya Pembelajaran Mesin". Tapi sebab SEO dan perkataan pembelajaran mesin tak digunakan secara meluas dalam bahasa Malaysia, saya ubah tajuk dan guna perkataan Kepintaran Buatan.
Saya teruskan usaha penterjemahan ini, sebab artikel dalam siri ini, sebab saya suka artikel siri ini. Mudah faham.
Saya sedaya upaya menterjemah sedekat mungkin dengan maksud penulis asal. Walaubagaimanapun, untuk orang ramai lebih mudah faham, saya akan mencelah dan mengubah struktur ayat sedikit sebanyak.
Ada masalah? Tak setuju dengan terjemahan saya? Ada pendapat? Komen di bawah atau tweet saya.
Penerangan Mendalam Tentang Kepintaran Buatan yang Mudah Difahami (Bahagian 2)
Dalam bahagian 1, kita menyatakan Pembelajaran Mesin (ML) ialah menggunakan algoritma umum untuk menyampaikan sessuatu yang menarik berkaitan dengan data, tanpa menulis sebarang kod tertentu (khusus) bagi menyelesaikan sesuatu masalah. (Kalau anda tak baca lagi bahagian 1, baca sekarang!)
Kali ini, kita akan menyaksikan salah satu daripada algoritma umum yang menghasilkan sesuatu yang hebat. Iaitu membina level dalam permainan video yang kelihatan seolah-olah hasil air tangan manusia. Kita akan membina satu rangkaian neural (Neural Network). Kita suap level dalam Super Mario yang sedia ada, kemudian satu level baru akan tercipta.
Sama seperti bahagian 1, tunjuk ajar ini ditujukan hanya kepada mereka yang bersungguh-sungguh nak belajar tentang pembelajaran mesin. Tetapi tak tahu bagaimana nak mula. Tujuan siri artikel ini, supaya boleh difahami oleh semua orang. Maksudnya, artikel ini akan menerangkan secara umum dan kita akan langkau banyak bahagian yang lebih mendalam. Tapi, siapa peduli? Seandainya, artikel ini dapat menarik hati seseorang menjadi semakin minat nak tahu tentang pembelajaran mesin, maka misi selesai.
Buat Tekaan Yang Lebih Bijak
Sebelum ini, artikel bahagian 1, kita buat satu algoritma mudah yang menjangka harga sesebuah rumah berdasarkan ciri-cirinya. Diberikan data tentang sebuah rumah seperti berikut:

Kita berakhir dengan fungsi jangkaan mudah seperti berikut:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * 0.123
# and a big pinch of that
price += sqft * 0.41
# maybe a handful of this
price += neighborhood * 0.57
return priceDalam kata lain, kita teka harga sesebuah rumah dengan cara mendarab setiap ciri-cirinya dengan suatu pekali. Kemudian kita hanya tambah semua nombor-nombor tersebut untuk mendapatkan harga rumah.
Daripada kita koding, jom kita tunjukkan fungsi yang sama dalam bentuk gambarrajah mudah:
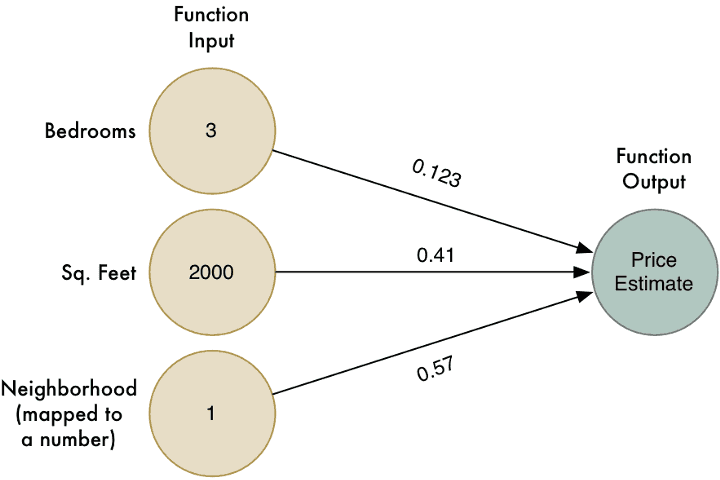
Walaubagaimanapun, algoritma ini hanya berfungsi untuk masalah mudah yang mana keputusannya berkait secara langsung dengan data yang diterima. Macammana kalau harga sebenar sebuah rumah tak semudah yang disangka? Contoh, mungkin faktor kejiranan sangat mempengaruhi harga, hanya untuk rumah-rumah yang bersaiz besar dan kecil, tetapi tidak kepada rumah-rumah saiz sederhana. Bagaimana kita nak tangkap isu yang agak kompleks ini dalam model kita?
Bagi menjadikan ianya lebih bijak, kita boleh jalankan algoritma ini banyak kali dengan pekali yang berbeza dan masing-masing dengan situasi yang berbeza:
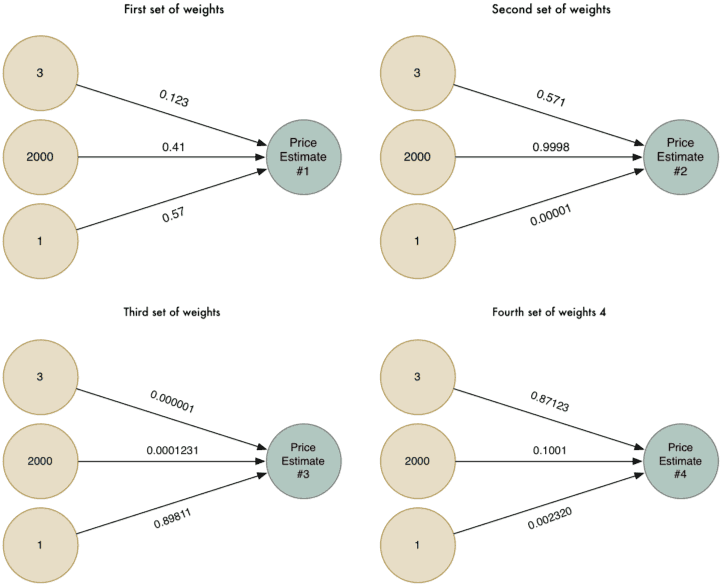
Sekarang kita ada 4 jangkaan harga yang berbeza. Jom kita gabungkan keempat-empat jangkaan harga tadi kepada satu jangkaan akhir. Kita akan jalankan kesemuanya melalui satu algoritma yang sama sekali lagi (tapi berlainan kumpulan pekali)!
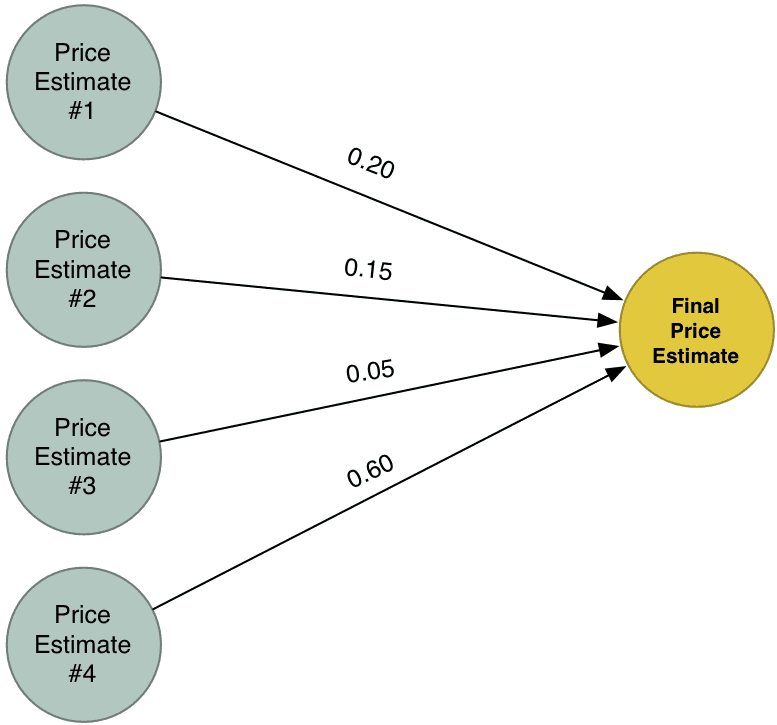
Jawapan Terbaik kita yang baru, menggabungkan jangkaan daripada empat cubaan berbeza kita dalam menyelesaikan masalah. Sebab itu, ia boleh membina menimbang tara lebih banyak situasi berbanding dengan apa yang kita boleh dapat dalam satu situasi mudah.
Apa itu Rangkaian Neural (Neural Network)?
Mari gabungkan keempat-empat cubaan kita tadi dalam satu gambarajah besar:
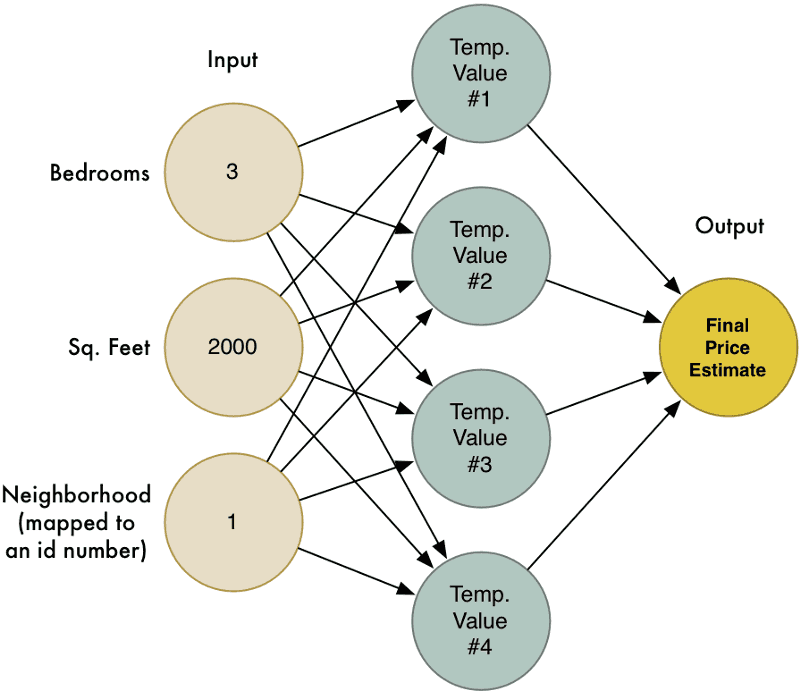
Inilah rangkaian neural! Setiap nod tahu cara nak dapatkan kumpulan data, mengenakan pekali ke atasnya dan seterusnya mengira nilai hasil. Dengan merantaikan bersama kesemua nod-nod ini, kita boleh menghasilkan fungsi model yang kompleks.
Terdapat banyak perkara yang saya langkau dalam usaha memudahkan penerangan (termasuk ciri perskalaan, feature scaling dan fungsi pengaktifan, activation function), tetapi bahagian paling mustahak adalah idea-idea ini masuk:
-
Kita buat satu fungsi jangkaan mudah yang mengambil satu kumpulan data dan mendarabkan dengan pekali untuk mendapat satu output. Kita sebut fungsi mudah ini sebagai neuron
-
Dengan merantaikan pelbagai neuron bersama, kita boleh menghasilkan fungsi yang sangat kompleks untuk satu neuron
Macam LEGO! Kita tidak boleh menghasilkan model dengan satu blok LEGO, tapi kita boleh menghasilkan pelbagai jenis model jika kita ada banyak blok LEGO digabung bersama:

Berikan Memori kepada Rangkaian Neural (neural network) kita
Rangkaian neural yang kita lihat akan sentiasa memberi jawapan yang sama apabila diberi maklumat data yang sama. Ia tiada memori. Ia tidak ingat perkara yang lepas. Dalam terma pengaturcaraan, disebut algoritma tanpa keadaan, stateless algorithm
Dalam kebanyakan kes (macam menjangka harga rumah), itulah yang anda nak. Tetapi, satu perkara yang model sebegini tidak boleh buat ialah, mengambil kira pola data berdasarkan masa.
Bayangkan saya beri anda papan kekunci dan minta anda tulis satu cerita (dalam bahasa Inggeris). Tetapi, sebelum anda mula, kerja saya meneka huruf pertama untuk perkataan yang anda akan taip. Huruf apa yang saya akan teka?
Saya boleh guna pengetahuan bahasa Inggeris untuk meneka dengan lebih tepat. Contoh, anda mungkin akan menggunakan perkataan yang selalu digunakan sebagai perkataan permulaan ayat. Jika saya tengok cerita-cerita yang anda pernah tulis, saya boleh kecilkan lagi skop kepada perkataan-perkataan yang anda selalu guna sebagai pemula ayat. Setelah saya dapat semua data itu, saya boleh gunakannya untuk buat satu rangkaian neural model mengenal pasti, betapa besar kemungkinan anda menggunakan huruf yang diberi sebagai pemula ayat.
Model kita mungkin akan kelihatan seperti berikut:

Tapi, jom kita jadikan masalah lagi susah. Katakan saya perlu meneka huruf seterusnya yang anda akan taip pada mana-mana tempat dalam cerita yang anda karang. Ini barulah masalah yang lagi mencabar.
Kita gunakan beberapa perkataan pertama dalam The Sun Also Rises oleh Ernest Hemingway sebagai contoh:
Robert Cohn was once middlewight boxi
Huruf apa yang akan muncul seterusnya?
Anda mungkin meneka huruf 'n', dan perkataannya mungkin boxing. Kita semua tahu tentang ini berdasarkan huruf-huruf yang kita pernah lihat dalam ayat dan pengetahuan asas bahasa Inggeris kita. Tambahan, perkataan 'middleweight' memberi klu tambahan, bahawa kita sedang bercerita tentang tinju (boxing).
Dalam kata lain, agak senang untuk meneka huruf seterusnya jika kita mengambil kira susunan huruf yang datang sebelumnya dan digabungkan dengan pengetahuan tentang bahasa Inggeris.
Bagi menyelesaikan masalah ini dengan rangkaian neural, kita hendaklah menambah state (keadaan) kepada model kita. Setiap kali kita tanya rangkaian neural untuk suatu jawapan, kita juga akan menyimpan kumpulan kiraan perantara (intermediate calculations) dan guna semula mereka sebagai sebahagian dari input untuk lain kali. Melalui cara sebegitu, model kita mengubah tekaan berdasarkan input terbaru yang diperolehinya.
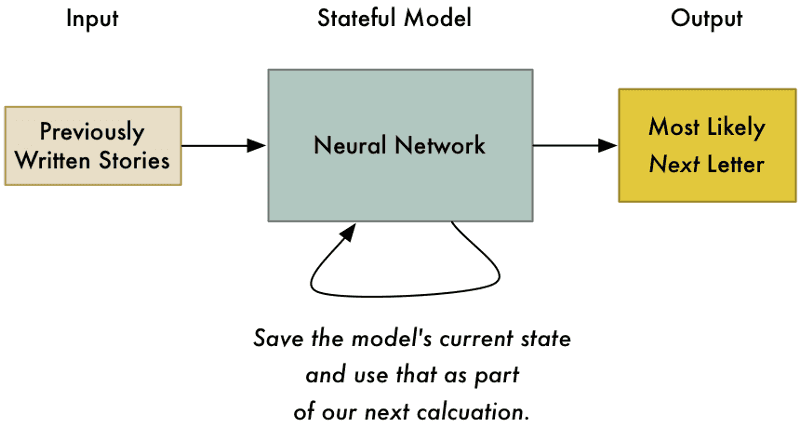
Menyimpan senarai keadaan ke dalam model, bukan sahaja membolehkan kita meneka huruf pertama dalam cerita kita, malahan boleh meneka huruf seterusnya berdasarkan huruf-huruf sebelumnya.
Inilah asas kepada idea Rangkaian Neural Berulang (Recurrent Neural Network). Kita mengemaskini rangkaian setiap kali kita menggunanya. Ini membenar model dikemaskini tekaannya berdasarkan apa yang terkini dilihatnya. Ia juga boleh merangka pola mengikut masa selagi mana kita memberinya memori secukupnya.
Apalah bagus sangat dengan sebiji huruf?
Meneka huruf seterusnya dalam satu cerita mungkin kelihatan sangat tidak berguna. Jadi, kenapa membazir masa?
Salah satu daripada adaptasi ialah fungsi tekaan-automatik (auto-predict) untuk papan kekunci telefon pintar:
Tapi, apa kata kita ambil idea ini ke arah yang lebih GANAS? Apa kata, kita minta model ini untuk meneka huruf terbaik secara berterusan, selamanya? Kita telah meminta algoritma ini untuk mengarang satu cerita yang sempurna untuk kita. Mungkin, boleh buat novel kot? Sebuah novel yang dikarang oleh AI?
Menjana sebuah cerita
Kita telah nampak bagaimana kita boleh meneka huruf seterusnya dalam ayat Hemmingway. Jom kita cuba menjana satu cerita penuh dengan gaya Hemmingway.
Untuk tujuan ini, kita akan menggunakan implementasi Rangkaian Neural Berulang, Reccurrent Neural Network, RNN oleh Andrej Karpathy. Andrej merupakan pengkaji Pembelajaran-Mendalam (Deep Learning) di Stanford dan telah menulis artikel yang terbaik memperkenalkan cara menjana teks menggunakan RNN. Anda boleh melihat kod untuk model ini di github.
Fakhrul mencelah. Saya pun nak cuba bermain dengan kod ini dan mungkin akan merakam screencast.
Kia akan membina model daripada teks The Sun Also Rises, 362,239 aksara menggunakan 84 unik aksara (termasuk tanda kata, huruf kecil, huruf besar dll). Kumpulan data ni, sebenarnya sangat lah kecil jika nak dibandingkan penggunaan aplikasi dunia sebenar. Bagi menghasilkan satu model yang sangat bagus untuk menulis gaya Hemmingway, adalah lebih baik jika kita gunakan berkali ganda banyak teks contoh. Tetapi, sekadar untuk bermain-main dengan algoritma, data sebanyak ini pun memadai.
Selepas kita mula melatih RNN, ia sangat tidak pandai untuk meneka huruf seterusnya. Ini contoh hasil selepas melalui 100 kali ulangan latihan:
hjCTCnhoofeoxelif edElobe negnk e iohehasenoldndAmdaI ayio pe e h’e btentmuhgehi bcgdltt. gey heho grpiahe.
Ddelnss.eelaishaner” cot AAfhB ht ltny
ehbih a”on bhnte ectrsnae abeahngy
amo k ns aeo?cdse nh a taei.rairrhelardr er deffijha
Anda boleh lihat ia faham sesuatu, contohnya kadang-kala di antara perkataan adanya senggang, tapi tu je.
Selepas 1000 lelaran (ulangan), keadaan menunjukkan hasil yang lebih baik:
hing soor ither. And the caraos, and the crowebel for figttier and ale the room of me? Streat was not to him Bill-stook of the momansbed mig out ust on the bull, out here. I been soms
inick stalling that aid.
“Hon’t me and acrained on .Hw’s don’t you for the roed,” In’s pair.”
“Alough marith him.”
Model ini mula mengenal pola untuk struktur asas sesuatu ayat. Ia akan meletakkan noktah pada setiap pengakhir ayat, malah menggunakan tanda pembuka dan penutup kata untuk teks cakapan. Beberapa perkataan boleh dikenal pasti, tetapi masih ada perkataan yang tak wujud.
Tetapi selepas beberapa ribu ulangan lagi, ia kelihatan agak baik:
He went over to the gate of the café. It was like a country bed.
“Do you know it’s been me.”
“Damned us,” Bill said.
“I was dangerous,” I said. “You were she did it and think I would a fine cape you,” I said.
“I can’t look strange in the cab.”
“You know I was this is though,” Brett said.
“It’s a fights no matter?”
“It makes to do it.”
“You make it?”
“Sit down,” I said. “I wish I wasn’t do a little with the man.”
“You found it.”
“I don’t know.”
“You see, I’m sorry of chatches,” Bill said. “You think it’s a friend off back and make you really drunk.”
Pada saat ini, algoritma telah berjaya menangkap corak akar gaya Hemmingway iaitu, dialog yang pendek dan terus. Beberapa ayat pun mula memberi maksud.
Bandingkan dengan teks sebenar dari dalam buku:
There were a few people inside at the bar, and outside, alone, sat Harvey Stone. He had a pile of saucers in front of him, and he needed a shave.
“Sit down,” said Harvey, “I’ve been looking for you.”
“What’s the matter?”
“Nothing. Just looking for you.”
“Been out to the races?”
“No. Not since Sunday.”
“What do you hear from the States?”
“Nothing. Absolutely nothing.”
“What’s the matter?”
Walaupun sekadar melihat pola untuk satu huruf pada satu masa, algoritma kita berjaya menghasilkan prosa yang munasabah dengan format yang betul. Hal ini sangat menarik!
Kita tidak perlu pun menjana teks dari kosong. Kita boleh benihkan algoritma ini dengan menyatakan beberapa huruf awal dan membiarkan model ini mencari huruf seterusnya.
Saja-saja nak seronok, jom kita buat satu kulit buku palsu untuk novel imiginasi kita. Kita akan menjana nama penulis dan tajuk buku rekaan dengan benih-benih "Er", "He" dan "The S":

Boleh tahan hebat!
Tapi perkara yang boleh buat 'terkejut beruk' ialah apabila algoritma ini boleh melihat pola untuk pelbagai jenis turutan data. Ia dengan senangnya boleh menjana resepi yang nampak betul-betul boleh jadi masakan atau ucapan palsu Obama. Tetapi kenapa hadkan diri kita dengan perkataan manusia? Kita boleh mengaplikasi idea yang sama untuk pelbagai jenis data berturutan yang ada pola.
Buat Mario tanpa betul-betul buat Mario
Pada tahun 2015, Nintendo melepaskan Super Mario MakerTM untuk konsol permainan Wii U.

Permainan ini membenarkan anda untuk membina level Super Mario Brother anda sendiri dengan gamepad dan kemudian memuatnaiknya ke internet supaya kawan-kawan anda boleh bermain melaluinya. Anda boleh memasukkan semua power-ups klasik dan musuh-musuh dari permainan Mario original dalam level anda. Ini seolah-olah satu set LEGO maya untuk orang-orang yang membesar dengan bermain Super Mario Brothers.
Fakhrul mencelah:
Masa kecil, saya orang kampung dan bukan yang jenis main game konsol. Jadi, saya tak de rasa nostalgia tentang game ni.
Ingat-ingat lupa. Pernah main dengan gameboy kawan kot...
Boleh tak kita guna model sama yang menjana teks palsu gaya Hemmingway tadi untuk membina level Super Mario Brothers?
Mula-mula, kita perlukan data set untuk melatih model kita. Jom kita lihat semua level outdoor dari permainan Super Mario Brothers original yang dilepaskan pada tahun 1985:

Permainan ini ada 32 level dan kurang lebih 70% daripadanya mempunyai gaya outdoor yang sama. Jadi, itu sahaja yang akan jadi sumber kita.
Untuk mendapatkan reka bentuk bagi setiap level, saya mengambil satu salinan original permainan tersebut dan menulis satu program yang boleh menarik reka bentuk level daripada memori permainan. Super Mario Bros. merupakan sebuah permainan berusia 30 tahun dan terdapat banyak sumber di internet yang anda boleh cari bagaimana level disimpan di dalam permainan memori. Data level yang diekstrak daripada permainan lama ini juga satu proses pengaturcaraan yang seronok, mungkin anda pun perlu cuba.
Ini level pertama daripada permainan tersebut (mungkin anda pun ingat yang anda pernah main dulu):

Jika kita lihat lebih dekat, kita akan perasan yang level ini terbina daripada grid ringkas beberapa objek:

Kita boleh juga dengan senangnya mempersembahkan balik grid-grid ini dalam bentuk susunan aksara dengan setiap aksara mewakili suatu objek:
--------------------------
--------------------------
--------------------------
#??#----------------------
--------------------------
--------------------------
--------------------------
-##------=--=----------==-
--------==--==--------===-
-------===--===------====-
------====--====----=====-
=========================-Kita gantikan setiap objek dalam level ini dengan huruf:
- - ruang kosong
- = blok keras
- # bata boleh pecah
- ? block koin
- ... dan seterusnya, menggunakan huruf berbeza untuk objek yang berbeza dalam level tersebut.
Saya akhirnya berjaya menghasilkan fail teks seperti berikut:

Melihat kepada fail teks, anda akan dapat lihat bahawa level dalam Mario tak lah ada banyak sangat pola jika anda lihat baris demi baris:

Pola untuk satu level sangat menyerlah apabila kita fikirkan setiap level secara menegak:
Jadi dalam proses untuk algoritma ini mencari pola dalam data kita, kita perlu masukkan data secara lajur demi lajur. Mencari cara paling efektif mempersembahkan data anda (disebut sebagai pemilihan ciri feature selection) merupakan salah satu dari kunci membina algoritma pembelajaran mesin yang baik.
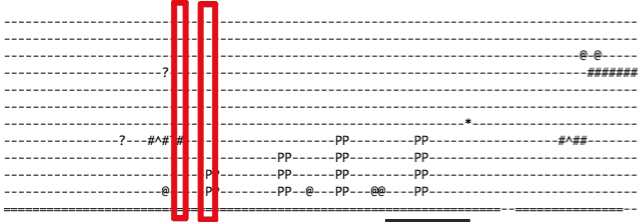
Untuk melatih model ini, saya perlu pusing fail teks tadi secara 90 darjah. Ini memastikan setiap aksara dimasukkan ke dalam model melalui keadaan pola lebih mudah kelihatan:
-----------=
-------#---=
-------#---=
-------?---=
-------#---=
-----------=
-----------=
----------@=
----------@=
-----------=
-----------=
-----------=
---------PP=
---------PP=
----------==
---------===
--------====
-------=====
------======
-----=======
---=========
---=========Melatih model kita
Seperti yang kita lihat semasa membina model untuk prosa Hemmingway, model semakin baik bila dlatih dengan lebih banyak.
Setelah latihan yang sekejap, model kita akan hanya mampu menghasilkan sampah:
--------------------------
LL+<&=------P-------------
--------
---------------------T--#--
-----
-=--=-=------------=-&--T--------------
--------------------
--=------$-=#-=-_
--------------=----=<----
-------b
-Ia seolah-olah dapat idea tentang simbol - dan = sepatutnya muncul dengan banyak kali, tetapi itu sahaja. Ia belum mampu melihat pola data lagi.
Setelah seribu lelaran latihan, ia mula kelihatan seperti:
--
-----------=
----------=
--------PP=
--------PP=
-----------=
-----------=
-----------=
-------?---=
-----------=
-----------=Model ini mula mengecam bahawa setiap baris seharusnya sama panjang. Ia juga mula dapat kenal pasti logik dalam permainan Mario: Paip dalam Mario selalunya 2 blok lebar dan sekurang-kurangnya 2 blok tinggi, jadi huruf P dalam data perlu muncul dalam keadaan 2x2. Boleh tahan!
Dengan lebih banyak latihan, model kita sampai ke tahap boleh menjana data yang sah sempurna:
--------PP=
--------PP=
----------=
----------=
----------=
---PPP=---=
---PPP=---=
----------=Jom lihat contoh penuh data untuk seluruh level dari model kita dan pusingkannya menjadi melintang balik:

Data ini nampak mantap! Terdapat beberapa yang hebat kalau anda perasan:
- Model kita meletakkan Lakitu (raksasa yang terapung atas awan) atas langit pada mula permulaan level, sama macam dalam level Mario sebenar
- Model kita tahu tentang paip yang terapung atas awan perlu terletak atas blok keras dan bukan sekadar terapung
- Model kita meletakkan musuh di tempat yang rasional
- Model kita tidak meletakkan sesuatu yang boleh menghalang pemain dari maju ke depan sampai akhir
- Model kita memberikan rasa seperti bermain dari level Super Mario Bros sebenar. Sebab ia berdasarkan level gaya original yang sedia ada dalam permainan.
Akhir sekali, mari kita ambil level ini dan buat semula di Super Mario Maker:

Cuba main sendiri!
Sekiranya anda ada Super Mario Maker anda boleh main level ini dengan klik penandanya di internet atau dengan cara mencari level code 4AC9-0000-0157-F3C3
Pengaplikasian Mainan lwn Dunia Nyata
Model algoritma Rangkaian Neural Berulang yang kita latih di atas, agak serupa dengan algoritma yang digunakan oleh syarikat dalam dunia sebenar untuk menyelesaikan masalah speech detection dan terjemahan bahasa. Kita bina model kita sebagai "mainan" berbanding dengan cutting-edge sebab model kita dibina berdasarkan data yang sangat sikit. Masalahnya kita tidak mempunyai data level yang mencukupi dalam permainan orignal Super Mario Brothers untuk menyediakan data yang cukup bagi menghasilkan model yang baik.
Jika kita dapat akses kepada beratus ribu level Super Mario Maker yang dibuat oleh pengguna sebagaimana dipunyai oleh Nintendo, kita mungkin boleh menghasilkan model yang terbaik. Tetapi, sayangnya kita tidak, sebab Nintendo tidak akan serahkan kepada kita. Syarikat-syarikat besar tidak akan menyerahkan data mereka secara percuma.
Apabila pembelajaran mesin (ML) menjadi semakin penting kepada industri, beza antara perisian yang baik dan kurang bergantung kepada jumlah data yang digunakan untuk melatih model. Hal ini, menyebabkan syarikat seperti Google dan Facebook sangat berkehendakkan data bersungguh-sungguh.
Sebagai contoh, Google melepaskan TensorFlow sebagai sumber terbuka. TensorFlow ialah sebuah toolkit perisian untuk membina aplikasi pembelajaran mesin berskala besar. Hal ini merupakan perkara yang sangat besar kepada Google yang mampu memberi produk sehebat ini secara percuma. TensorFlow juga adalah toolkit yang digunakan oleh Google Translate.
Tapi, tanpa data yang berlambak dalam semua bahasa sebagaimana yang dipunyai oleh Google. anda tidak akan mampu menghasilkan pesaing kepada Google Translate. Jumlah data lah yang menjadikan Google berada pada tahap sekarang. Di lain masa, apabila anda buka sejarah lokasi Google Maps atau sejarah lokasi Facebook, cuba fikir. Anda akan perasan bahawa tempat-tempat yang pernah anda pergi disimpan.
Bacaan lanjut
Dalam pembelajaran mesin, tidak pernah ada satu cara sahaja untuk selesaikan masalah. Anda ada infiniti pilihan cara untuk melakukan pra-proses data anda dan algoritma yang ingin digunakan. Selalunya, menggabungkan beberapa pendekatan akan memberikan anda hasil yang lebih memuaskan berbanding dengan satu pendekatan.
Pembaca lain juga menghantarkan pautan-pautan menarik tentang pendekatan untuk menghasilkan level Super Mario:
-
Justin Michaud meluaskan pendekatan yang saya gunakan untuk menjana level dan menjumpai cara untuk menjana level untuk fail rom NES yang original (kod ditulis 30 tahun lepas)! Anda pun boleh bermain level yang digodamnya di rom yang digodam atas talian.
-
Kumpulan Amy K. Hoover's menggunakan pendekatan setiap jenis objek dalam level (paip, tanah, platfom, etc) sebagai satu suara dalam kesuluruhan simfoni. Menggunakan proses yang dipanggil functional scaffolding, sistem akan menambah level dengan blok untuk segala jenis objek yang diberikan. Contohnya, anda boleh melukis bentuk asas untuk setiap level, boleh menambah paip dan blok soalan untuk menyiapkan reka bentuk anda.
-
Kumpulan Steve Dahlskog mempamerkan model untuk data setiap lajur dalam level sebagai satu n-gram siri. Hal ini membolehkan proses jana level dengan algoritma yang lebih mudah berbanding Rangkaian Neural Berulang,RNN yang besar.
Fakhrullah mencelah:
Alhamdulillah berjaya jugak terjemah artikel bahagian 2 ni. Laman web Pusat Rujukan Persuratan Melayu pun dah berwajah baru, lagi senang nak guna. Tahniah DBP!!, baru nampak berkerja. Cuma, kalau boleh usahakan juga https. Tapi, tak pasti dengan datanya, ada pertambahan baru atau tidak.
Cuma masalah sekarang ni, semua bacaan dan terjemahan ni sekadar teori. Tak tahu bila nak masuk pratikal. Nak kena cari masa buat, baru lagi faham.
Antara idea yang menarik nak saya cuba ialah, kira harga makanan dalam pinggan dengan ambil gambar sahaja dan sebab sayangkan bahasa, algoritma untu tukar ucapan bahasa Melayu ke teks, speech to text.Macam biasa, kalau ada nampak salah, nak tambah, tinggalkan komen dibawah atau cuit saya dekat twitter @fajarhac.